The training images for this model can be found here.
I developed a machine learning model to colorize grayscale images of faces, leveraging its ability to add vibrant hues and bring monochrome portraits to life. Given the constraints of limited computing power, I opted to focus specifically on faces rather than attempting to create a generalized grayscale-to-color model, which would have required significantly more resources and likely yielded weaker results due to the diverse range of subjects. While the model can technically be applied to any grayscale image, its training on facial data ensures optimal performance and the most accurate colorization for images containing human faces.
Image Colorization
Below are the test results after training the model:

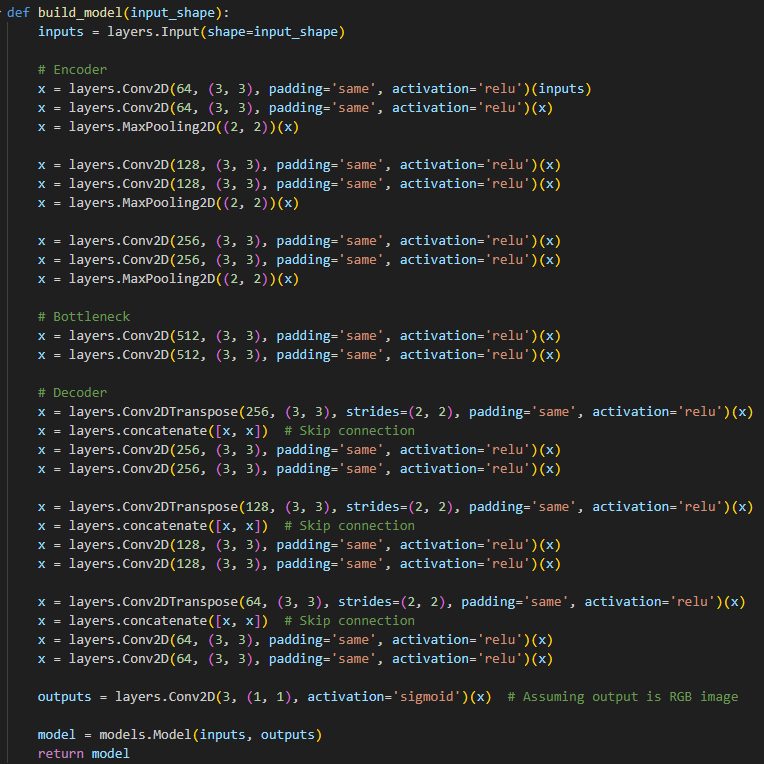
This model is a convolutional neural network (CNN) designed for image processing tasks, featuring an encoder-decoder architecture with skip connections. It processes input images and generates reconstructed outputs, making it suitable for applications like image segmentation, super-resolution, and image-to-image translation. The network is structured to progressively extract and reconstruct features, preserving spatial details and enabling high-quality outputs.
The encoder consists of convolutional (Conv2D) and max-pooling layers (MaxPooling2D), organized into three stages. Each stage extracts progressively higher-level features, starting with 64 filters for low-level details, followed by 128 and 256 filters for medium- and high-level representations, respectively. The encoder's max-pooling layers reduce the spatial dimensions while retaining key feature information.
At the network's core, the bottleneck contains two convolutional layers with 512 filters. This segment compresses the features into a compact representation, capturing the most abstract and essential characteristics of the input.
The decoder reconstructs the image using transposed convolutional layers (Conv2DTranspose) for upsampling and skip connections to integrate fine-grained details from the encoder. Each decoder stage restores spatial dimensions, beginning with 256 filters and reducing to 128 and 64 filters in subsequent stages. The output layer uses a convolutional layer with three filters and a sigmoid activation function, producing a normalized RGB image with pixel values between 0 and 1.
Overall, this model's symmetrical structure, skip connections, and small convolutional kernels ensure efficient feature extraction and reconstruction, making it highly versatile for image-to-image transformation tasks.